图解机器学习:分类模型性能评估指标
人间出现一种怪病,患病人群平时正常,但偶尔暴饮暴食,这种病从外观和现有医学手段无法分辨。
为了应对疫情,准备派齐天大圣去下界了解情况。事先神官从人间挑选了一些健康人和患病者来对大圣的业务能力进行测试,按下面规则来区分人群:
- 健康人站在绿色区域
- 患病者站在橙色区域

齐天大圣出场用他的火眼金睛识别哪些是健康人,哪些又是患病者。
随后画一个圈,告诉神官:圈里的是我认为健康的人,圈外的就是患病者。

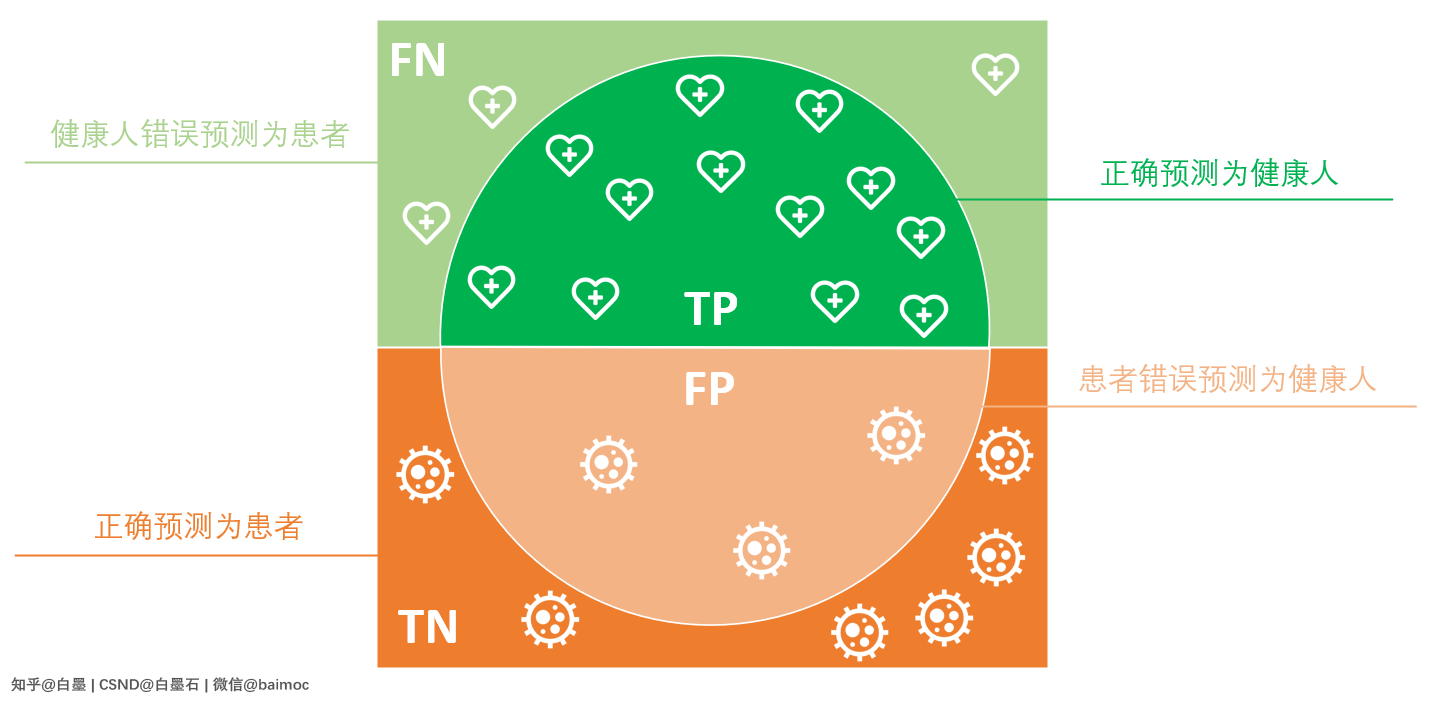
接下来,我们画个图来看看大圣火眼金睛的识别效果:
为了区分识别是否正确,我们让大圣识别正确的人站在深色区域,错误的站浅色区域,也就是:
- 深绿色(TP):正确识别为健康人
- 深橙色(TN):正确识别为患病者
- 浅绿色(FN):健康人错误识别为患者
- 浅橙色(FP):患者错误识别为健康人
我们发现大圣画的圈里大部分是正确的,但是也有少量错误。话说应该是大圣年纪大了。
一、混淆矩阵 Confusion Matrix
现在回到机器学习的监督学习中,为了方便绘制和展示,我们常用表格形式的混淆矩阵(Confusion Matrix)作为评估模式。这在无监督学习中一般叫做匹配矩阵。
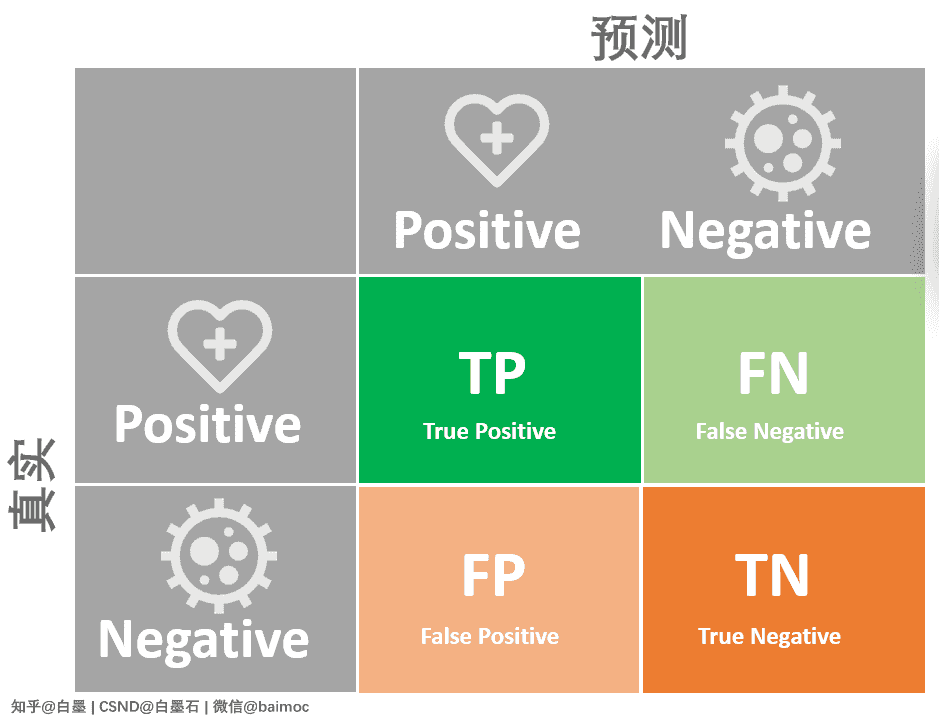
其中,
- 行代表真实数据:包含真实的健康者和患病者数目
- 列代表预测数据:包含预测的健康者和患病者数目
为了方便理解记忆,这里将健康者称为 Positive,患病者称为 Negative:
- True Positive(TP):本身为健康,预测为健康 (对健康人拿捏了)
- False Negative(FN):本身为健康,预测为患病(老倒霉蛋了)
- False positive(FP):本身为患病,预测为健康 (漏网之鱼了属于是)
- True Negative(TN):本身为患病,预测为患病 (对患病者拿捏了)
二、准确率 Accuracy
Accuracy:指模型识别正确的样本数占样本总数的比例。
也就是,正确识别的健康人和患者占全部人群的比例。
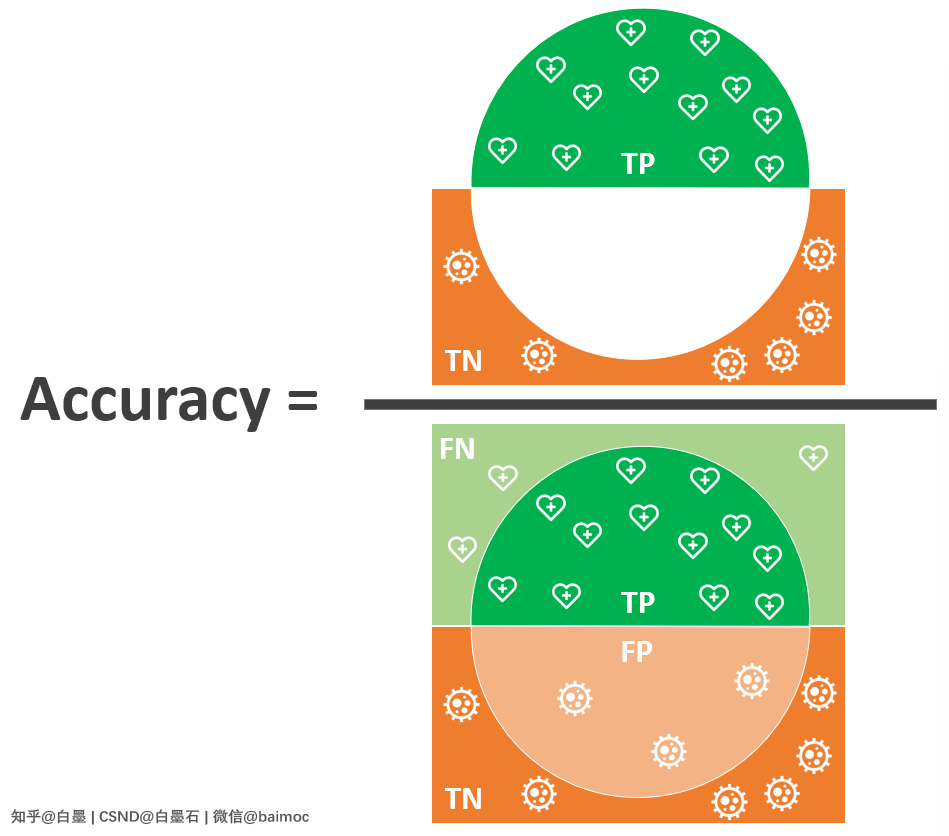
用公式表示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rxkqere4-1651725986989)(https://cdn.nlark.com/yuque/__latex/148a7f222cf675c78eb886c0b9215065.svg)]
Accuracy 是最常用的评估指标,可以总体上衡量一个预测的性能。
一般情况在数据类别均衡的情况下,模型的精度越高,说明模型的效果越好。
需要注意的是,但是在严重不平衡的数据中,这个评估指标并不合理。比如这个病毒的发病率为 0.1%,模型可以把所有人判定为健康人,模型 Accuracy 直接高达99.9%,但这个模型并不适用。
为了更好地应对上述问题,衍生出了一系列其他评估指标。
三、精度 Precision
Precision:在模型识别为 Positive 的样本中,真正为 Positive 的样本所占的比例。
也就是说,在识别为的健康人群中,有多少是真正健康的。
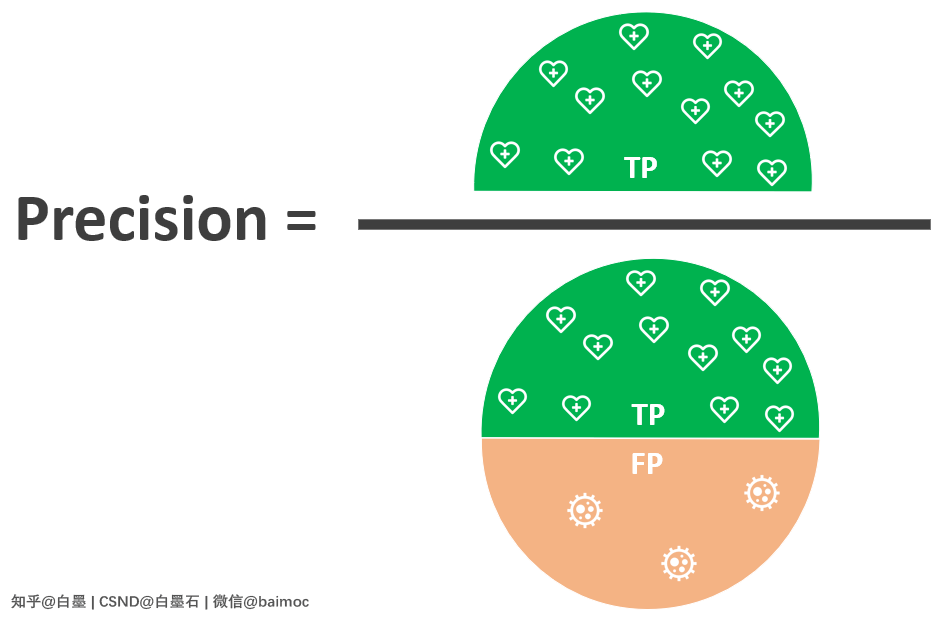
公式表示为:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XoZbeWBo-1651725986990)(https://cdn.nlark.com/yuque/__latex/cb23f4ec83e30b7e91bb509abe4e2353.svg)]
如果模型目标是:宁愿漏掉,不可错杀,我们应该更关注 Precision 指标。一般情况下,Precision 越高,说明模型的效果越好。
在识别垃圾邮件时,为了避免正常邮件被误杀,就需要模型有较高的 Percision。
四、召回率 Recall
Recall:模型正确识别出为 Positive 的样本数量占 Positive 数量的比值。
也就是说,在实际的健康人中,识别出的健康人比值。
Recall越高,代表模型从健康人群中识别出的健康人的比例越高。
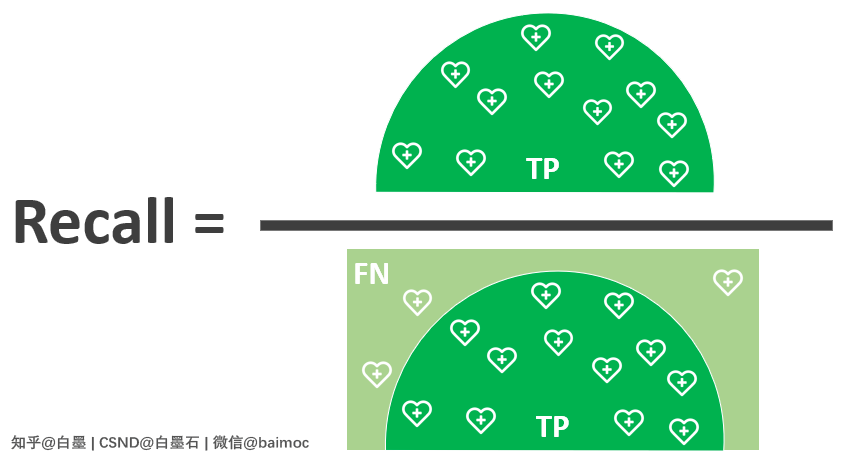
公式表示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-79ZNhZbE-1651725986992)(https://cdn.nlark.com/yuque/__latex/9f557d7c881df224be1389a6c9408b8f.svg)]
如果模型目标是:宁愿错杀,不可漏掉,我们应该更关注 Recall 指标。一般情况下,Recall 越高,说明模型的效果越好。
在金融风控领域中,目标是尽可能筛选出所有的风险行为或用户,避免造成灾难性后果。因此,需要更高的 Recall 值。
五、Fβ-Score 与 F1-Score
Precision和Recall都是越高越好,但这个两个指标间相互矛盾,此消彼长,因此无法保证二者都很高。
为了综合考虑 Precision 与 Recall,需要引入一个新指标 Fβ-Score:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NcEPCqwP-1651725986993)(https://cdn.nlark.com/yuque/__latex/25c96bc728f2420cafa058166dbba944.svg)]
更具不同的场景来调整 β值。
- β<1 时,更关注Precision。
- β>1 时,更关注Recall。
- β=1 时,Fβ-Score 就是 F1-Score,
当 F1-Score 值较高时则说明模型性能较好。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WdhLC3Bq-1651725986994)(https://cdn.nlark.com/yuque/__latex/55e3ddf7d2665455579f509c02dff962.svg)]
六、真正例率 True Positive Rate,TPR
TPR:在实际的 Positive 样本中,识别出的 Positive 样本比值。
也就是说,大圣在实际的健康人群中,识别出的健康人比值。
TPR 越高,代表模型从健康人群中识别出的健康人的比例越高。
TPR 值越高,模型性能越好。
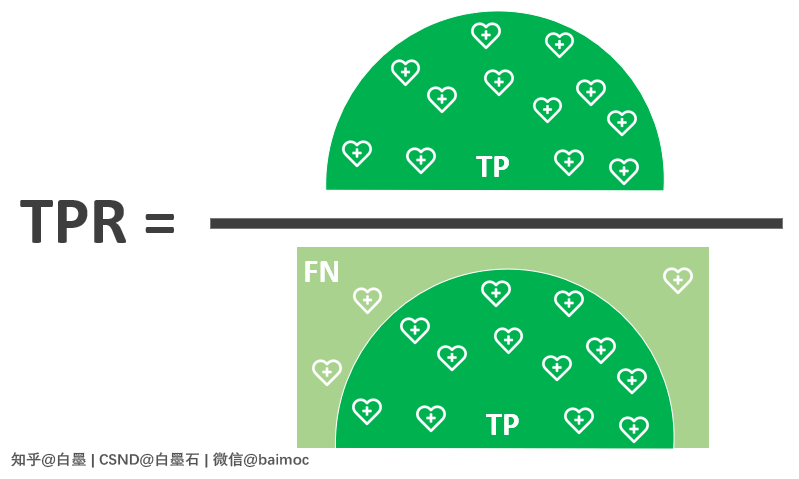
公式表示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2fKZGuug-1651725986998)(https://cdn.nlark.com/yuque/__latex/edb477ff28540cb8ca888b131e5f901f.svg)]
七、假正例率 False Positive Rate,FPR
FPR:在实际的 Negative 样本中,错误识别为 Positive 的比值。
也就是说,在实际的患者中,错误识别为健康人的比值。
FPR 越高,代表模型从患病人群中识别出的健康人的比例越高。
FPR 越低,代表模型性能越好。
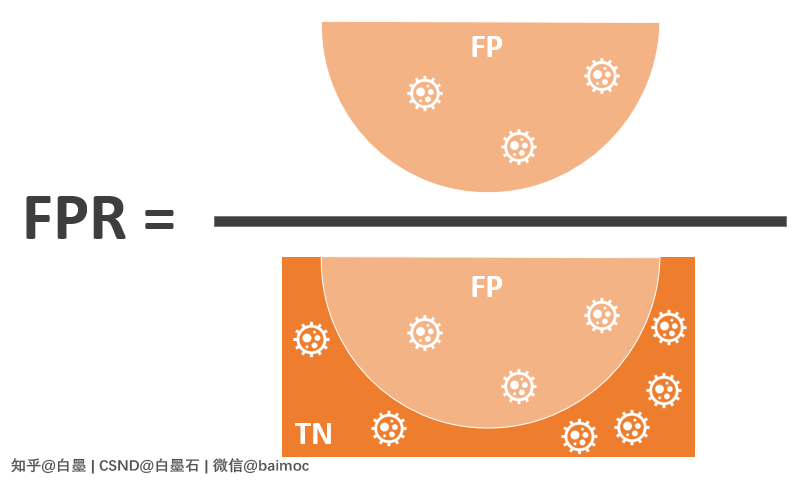
公式表示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MHYZKdSw-1651725987000)(https://cdn.nlark.com/yuque/__latex/9edd061fecffd6f8d702216f2cecd33b.svg)]
八、ROC 曲线
ROC曲线(Receiver Operating Characteristic Curve)通过 True Positive Rate(TPR,真正例率)和False Positive Rate(FPR,假正例率)两个指标的反映模型综合性能。
接下来,我们利用 TPR 和 FPR 绘制 ROC 曲线:
- ROC 不同颜色的曲线代表不同的模型
- 对角线的虚线代表随机分类,如果ROC位于左上角代表比随机分类好的模型,右下角为比随机分类差的模型
- 四个角分别代表不同的分类效果
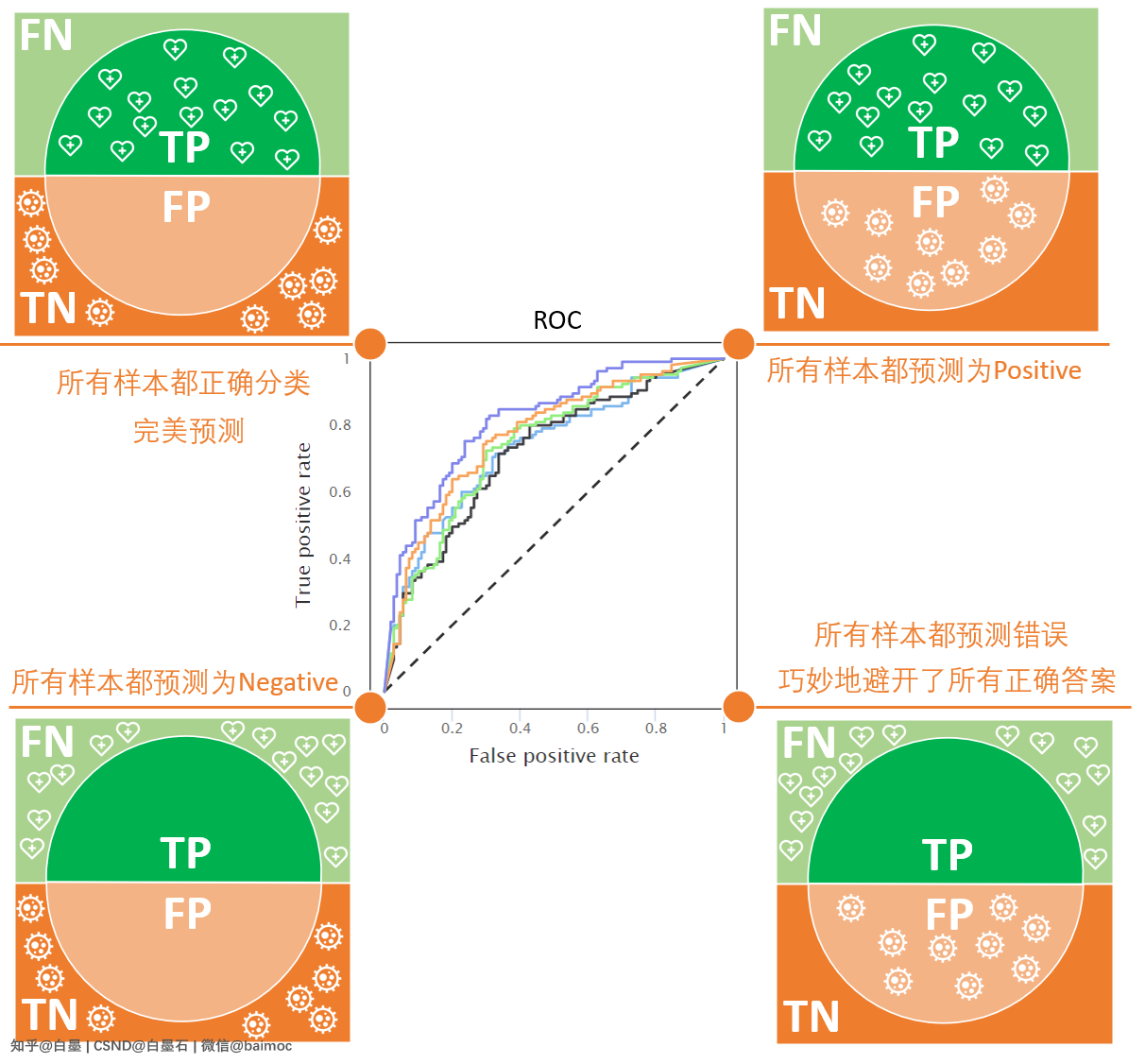
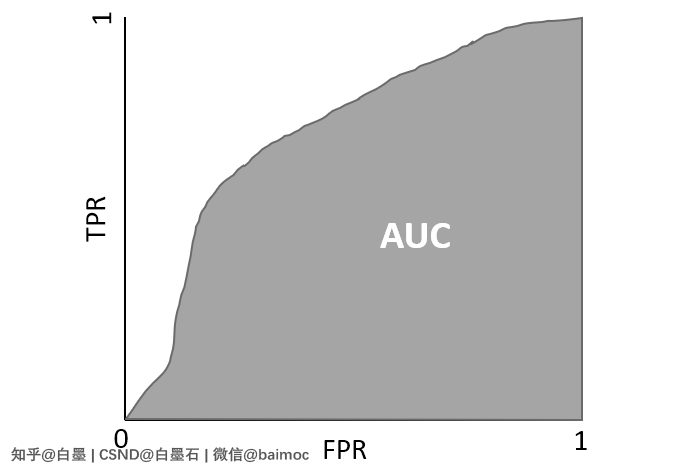
九、AUC 面积
ROC 曲线可以直观的反应模型性能,但是难以比较不同模型的差异。
计算ROC曲线右下角面积得到AUC,该指标可以实现对模型性能的定量化描述。
 微信
微信 支付宝
支付宝




