一、环境准备:
搭建 Python 高效开发环境: Pycharm + Anaconda
二、安装 scanpy
三、AnnData
1、AnnData 介绍与结构
AnnData 是用于存储数据的对象,一般作为 scanpy 的数据存储格式。
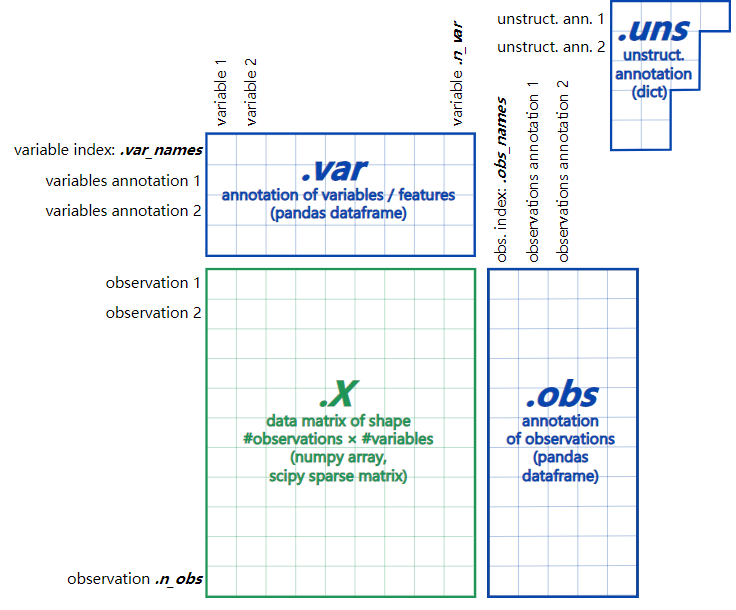
主要由以下几部分构成:
|
功能 |
数据类型 |
| adata.X |
矩阵数据 |
numpy,scipy sparse,matrix |
| adata.obs |
观察值数据 |
pandas dataframe |
| adata.var |
特征和高可变基因数据 |
pandas dataframe |
| adata.uns |
非结构化数据 |
dict |
下面我们动手构建一个用于创建 AnnoData 的虚拟数据
import numpy as np
import pandas as pd
import anndata as ad
from string import ascii_uppercase
n_obs = 1000
obs = pd.DataFrame()
obs['time'] = np.random.choice(['day 1', 'day 2', 'day 4', 'day 8'], n_obs)
var_names = [i*letter for i in range(1, 10) for letter in ascii_uppercase]
n_vars = len(var_names)
var = pd.DataFrame(index=var_names)
|
2、AnnoData 初始化
adata = ad.AnnData(X, obs=obs, var=var, dtype='int32')
adata = ad.AnnData(X, obs=obs, var=var, dtype='int32')
print(adata)
|

3、AnnoData 切片特性
可以看到 AnnData 具有和 dataframe 或 Array 相似的长相,同样具备相似的特性,比如切片:
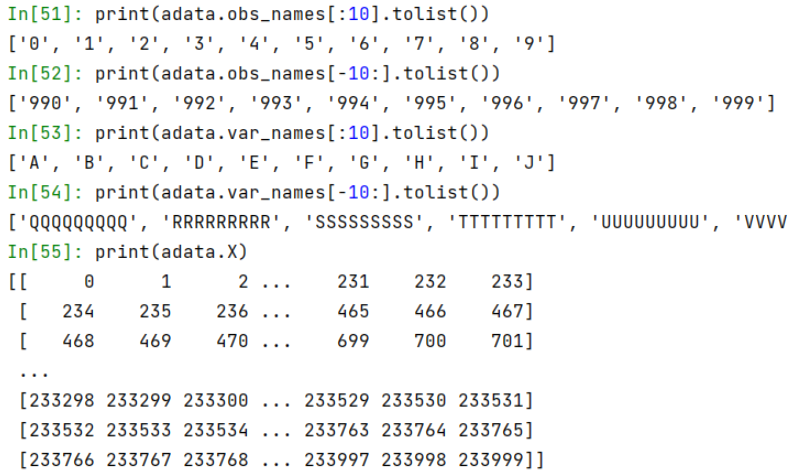
print(adata.obs_names[:10].tolist())
print(adata.obs_names[-10:].tolist())
print(adata.var_names[:10].tolist())
print(adata.var_names[-10:].tolist())
print(adata.obs_names[:10].tolist())
print(adata.obs_names[-10:].tolist())
print(adata.var_names[:10].tolist())
print(adata.var_names[-10:].tolist())
print(X)
|
3、AnnoData 的 view 特性
AnnoData 可以实现与 numpy 中的 view 相似的功能。
换句话说就是,我们每次操作 AnnoData 时,并不是再新建一个 AnnoData 来存储数据,而是直接找到已经之前初始化好的 AnnoData 的内存地址,通过内存地址来直接改变 AnnoData 的值。这样做的好处是:
- 无需分配多余的内存
- 可以直接修改已经初始化后的 AnnoData 对象
view 可以使用 .copy() 来得到 AnnoData 对象。
print(adata[:3, 'A'].X)
adata[:3, 'A'].X = [0, 0, 0]
print(adata[:5,
print(adata[:3, 'A'].X)
adata[:3, 'A'].X = [0, 0, 0]
print(adata[:5, 'A'].X)
|

其实我们在调用 .[] 时,AnnoData已经在内部实现了该操作,也就是说该 view 会成为保存数据的 AnnoData 对象。
但是,如果将 AnnoData 对象的 view 中的一部分赋值,该内容会复制一份并生成新的数据存储对象。
adata_subset = adata[:5, ['A', 'B']]
print(adata_subset)
adata_subset.obs['foo'] = range(adata_subset = adata[:5, ['A', 'B']]
print(adata_subset)
adata_subset.obs['foo'] = range(5)
|

可以看到,这时赋值会直接将 AnnoData 对象复制一份。现在 adata_subset 会重新得到一块内存用于存储实际数据,而不再仅仅是对 adata 的内存地址引用。
4、备份到本地
def print_size_in_MB(x):
print('{:.3} MB'.format(x.__sizeof__()/1e6))
print_size_in_MB(adata)
adata.isbacked
adata.filename = './write/test.h5ad'
|
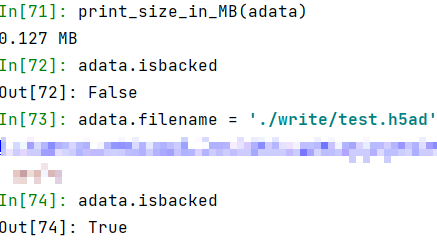
可以看到,我们的 adata 对象已经备份成功,而且就在本地 ‘./write/test.h5ad’ 目录。
前边提到的 view 特性在这里同样适用,我们来看看 adata_subset 是否备份成功。
adata_subset.isbacked
adata_subset.filename = adata_subset.isbacked
adata_subset.filename = './write/adata_subset_test.h5ad'
adata_subset.isbacked
|
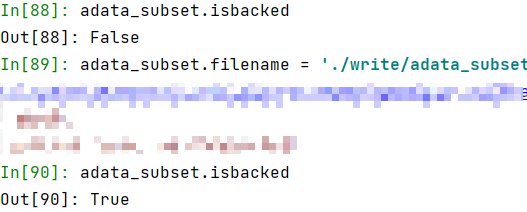
adata_subset 并没有被启用备份模式,重新设置备份模式。
需要注意的是:备份仅影响数据矩阵 X,所有注释信息都保留在内存中。如果想对全部数据的更改保存,则必须将导出到本地。
5、导出到本地
adata.write("./write/my_results.h5ad")
adata.write_csvs(adata.write("./write/my_results.h5ad")
adata.write_csvs('./write/my_results_csvs', )
|
6、读取数据
import scanpy as sc
import pandas as pd
adata = sc.read(filename)
anno = pd.read_csv(filename_sample_annotation)
adata.obs['cell_groups'] = anno['cell_groups']
adata.obs['time'] = anno['time']
|
官网:https://anndata.readthedocs.io/en/latest/
 微信
微信 支付宝
支付宝




